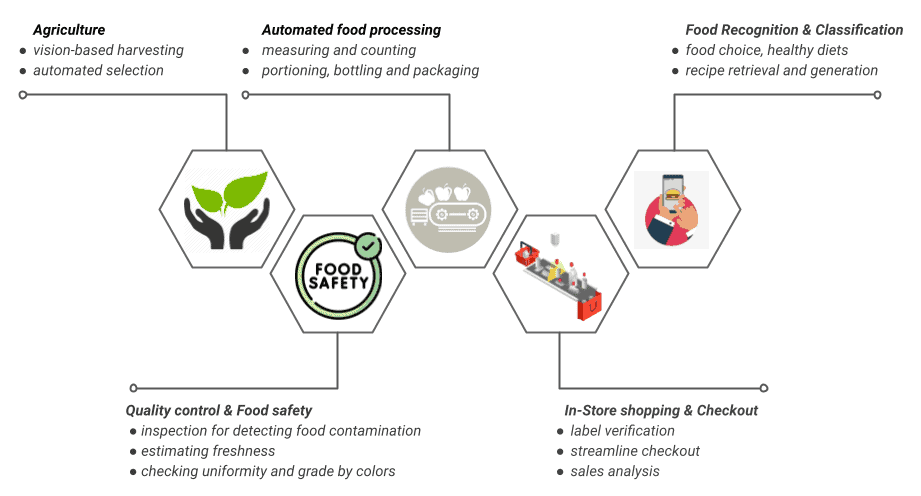
If you’ve ever come close to anything related to audio or other signal processing, you likely already know about spectrograms. Those fancy-looking and usually colorful plots are commonly used to represent a spectrum’s change over time. But can they provide us with some higher-level information about, let’s say, human speech? What if I told you that one could effectively get a transcript of a speech recording just from its spectrogram? Well, if you think that this is rather an exaggeration, you’re absolutely right. Yet, recognizing certain phonemes and even making educated guesses about specific words based only on their spectrograms is perfectly possible. Thus, let’s dive deeper into this topic and learn a thing or two about human speech on our way.
Power-Source-Filter Model
A common way to represent human speech is a so-called Power-Source-Filter model. The Power here refers to the lungs where an air flow originates, vocal cords are the Source of vibrations and everything above them (the vocal tract) serves as the Filter for those vibrations.

We can ignore the Power component for our current goal and focus only on the Source-Filter part. Using more accurate terms than just “vibrations,” the Source produces harmonic waves with a fundamental frequency depending on the voice pitch. The Filter then either amplifies or suppresses specific harmonics. Peaks on the filter’s frequency response are called formants and are denoted as F1, F2, etc. (from lower to higher frequency).

The Filter is considered linear, i.e. a current sample is approximated as a weighted sum of n previous samples. Given a speech recording, one can estimate coefficients of the Filter using a Linear Predictive Coding (LPC) technique and then use them to find the frequency response curve. We need this curve (specifically its formants) to help us recognize certain phonemes.
Read also:
Audio Processing Basics in PythonVowels
Phoneticians distinguish a set of 8 “cardinal vowels”, with each one being defined by a specific position of a tongue’s highest point while pronouncing it:

If we plot the highest point positions for each cardinal vowel together, they’ll form a specific figure:

If we make the same plot for frequencies of the first two formants (F1 and F2), it will look remarkably similar: 
The match isn’t perfect, of course (just as my pronunciation of the cardinal vowels, from which the formants were obtained), but it is still close enough. It leads to a couple of conclusions. First, even though the model with just the linear filter might look over-simplified, it bears direct correspondence with movements of the vocal tract. Second, the frequencies of the formants (usually two or three) are unique for each vowel and can be used to distinguish them.
To observe this, we can create a plot of a speech recording that is similar to a spectrogram but with the Filter’s frequency responses used as its columns instead of spectrums. Formants on this kind of plot are seen as bright horizontal lines. If we build it for a recording of several different vowels, it is evident that formants are indeed uniquely positioned for each of them:

Let us remember this plot for a future reference and move on to consonants.
Consonants
Unfortunately, there is no unique descriptor for each consonant, unlike formants for vowels. Instead, we can categorize consonants and use this classification to narrow down a list of possible options when trying to recognize a particular phoneme.
To analyze consonants, we need to pronounce them between two vowels, which makes them better defined on spectrograms. So, all examples were pronounced with two [a] sounds, like [apa], [ada], etc.
Arguably the most important category split is voiced and voiceless consonants. While pronouncing voiced ones, vocal cords still vibrate; thus, we can observe some harmonics. During voiceless ones, the vibration is absent, and harmonics are entirely interrupted. As evident from the following plot, while all consonants do look like “gaps” between vowels, voice ones ([b] and [d]) still leave some harmonics uninterrupted:

Fricatives can be recognized by a characteristic noise. Furthermore, the distribution of the noise along the spectrum can help to distinguish them from each other:

The frequency response can be helpful for consonants too. For instance, nasal consonants have a specific noise that is better observed on this kind of plot:

Trilled consonants ([r] in this case) can be easily spotted too by a very characteristic vertical pattern:

Some other features can help recognize consonants; however, they are more advanced and often harder to spot, so we’ll leave them out of scope for now.
Reading Words
Now, when we’ve learned to recognize different phonemes, why not try to do something more remarkable, like reading an actual word from a spectrogram? Here is one, with its spectrogram and corresponding frequency response plots:

We can immediately identify three separate vowels. Just by looking at the reference of different vowels that we’ve prepared earlier, we can pick the ones that look the most similar:

The second noticeable thing is three fricatives that can be identified by their noise using another reference from earlier:

Now we have just three missing phonemes. The first one can be easily recognized on the frequency response plot as a trilled consonant, with [r] being the only possible option in English. The second one is somewhat hard to identify, so we’ll skip it. Finally, the last missing one can also be identified on the frequency response plot as a nasal consonant (either [n] or [m]). So, here are our final predictions:

We still have one unknown consonant and ambiguity regarding another one, yet what we’ve discovered is enough to “brute force” the word, which is obviously “frequency”.
Conclusions
So, we’ve learned to recognize some phonemes on spectrograms. That is something you could brag about to a very limited number of people who would actually consider it cool but are there any practical applications to all this knowledge?
First, if you’re building any kind of speech processing pipeline with spectrograms as its inputs, you now know about features to look for and can tune spectrogram parameters to highlight them better. Or you can even use frequency responses for additional features. Also, if you have a speech-generating model (especially a black box one, like a neural network) and its output sounds wrong, you could compare its spectrogram to an actual speech and try finding the source of your troubles. And finally, what we’ve discussed in this post is present in many classic speech processing methods. Linear Predictive Coding, for example, is used for voice compression (like earlier versions of GSM), speech synthesis, speech encryption, audio codecs, etc. And it is always good to know the basics, even when working with much more advanced stuff.