In the previous article, we’ve learned what GStreamer is and its most common use cases. Now, it’s time to start coding in C++. This tutorial does not replace but rather complements the official GStreamer tutorials. Here we focus on using appsrc and appsink for custom video (or audio) processing in the C++ code. In such situations, GStreamer is used mainly for encoding and decoding of various audio and video formats.
GStreamer C++ Basics
GStreamer C++ API is introduced rather well in the official tutorial, I’ll give only a very brief introduction before focusing on appsrc and appsink, the most important topic of interest to us. Our tutorial can be found here. In our code, we use C++, not C. Also, unlike the official tutorial, we are not too eager to use GLib functions like g_print().
Let’s get going. Our first example, fun1, is an (almost) minimal C++ GStreamer example. Before doing anything with GStreamer, we have to initialize it:
gst_init(&argc, &argv);
It loads the whole infrastructure like plugin registry and such. But why does it need pointers to argc, argv? You can put nullptr, nullptr if you really want to. But honestly providing your command line arguments allows gst_init() to parse GStreamer-specific flags. For example, I always add –gst-debug-level=2 to the command line in order to log warnings and errors to the console (there’s no logging by default). Interestingly, GStreamer removes all its flags from argc, argv, so that you can later parse the remaining arguments.
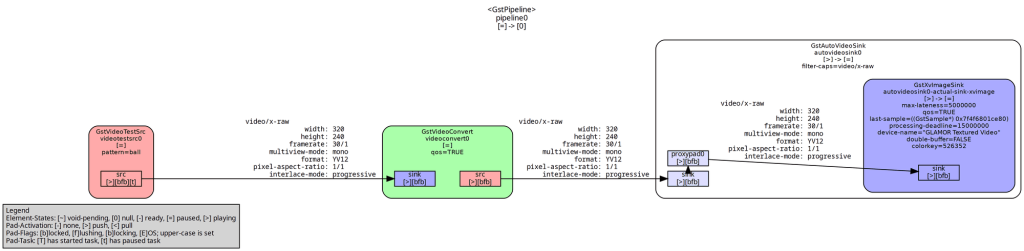
Next, we create a pipeline from a string
string pipelineStr = “videotestsrc pattern=0 ! videoconvert ! autovideosink”;
GError *err = nullptr;
GstElement *pipeline = gst_parse_launch(pipelineStr.c_str(), &err);
checkErr(err);
MY_ASSERT(pipeline);
Where MY_ASSERT is my assertion macro (like CV_ASSERT, never ever use the C++ assert statement !), and checkErr is my function that checks a GError object for errors, see the code for details. Checking for errors is important, to catch any typos in the pipeline string, linking failures etc. GStreamer is heavily based on GLib, especially on the GObject framework (a part of GLib), a pure C object-oriented framework. All GStreamer entities are GObject objects and they are handled as raw pointers. This may seem ugly compared to modern C++, but there is nothing I can do about it (as gstreamermm is now dead).
Now we created the pipeline, we should play it
MY_ASSERT(gst_element_set_state(pipeline, GST_STATE_PLAYING));
Is this all? Not yet. If we try to run the code at this point, it will simply run until the end of the main() function and shut down together with GStreamer, which didn’t even have time to start the pipeline properly. We must wait for the pipeline to finish. The simplest code for this is:
GstBus *bus = gst_element_get_bus (pipeline);
GstMessage *msg = gst_bus_timed_pop_filtered (bus, GST_CLOCK_TIME_NONE,
GstMessageType(GST_MESSAGE_ERROR | GST_MESSAGE_EOS));
gst_message_unref(msg);
gst_object_unref(bus);
GStreamer bus is a messaging system of a pipeline, which sends messages. Here we wait indefinitely for an error or end of stream (EOS), ignoring all other messages. Our further examples like fun2 demonstrate processing all messages in a loop, and eventually in a separate thread.
You might have asked: If our main() function is not blocked when the pipeline is running, then where does it run? In the other threads of course! GStreamer is multi-threaded and reasonably thread-safe (you can call the GStreamer function from different threads). There is NO such thing as GStreamer main loop. This can sound confusing, as many codes from the official tutorial use a GLib main loop. You absolutely don’t have to. The only point of this “main loop” is to block while watching the bus. As we watch the bus ourselves, we don’t need it. And it’s perfectly fine to use C++ threads with GStreamer, even though they didn’t exist when GStreamer was created (as they map into the same OS threads). GStreamer can also run several pipelines simultaneously if your PC is powerful enough for it.
Side note: The multi-threaded GStreamer philosophy is the opposite to the one of typical GUI libraries like Gtk+ or Qt, which run GUI strictly in a single thread with an event-processing main loop. GStreamer can be successfully combined with these libraries (see e.g. a Gtk+ example in the GStreamer tutorials), but this definitely goes beyond the scope of this article.
We are almost done with fun1. Now let’s exit the program cleanly by stopping and releasing the pipeline:
gst_element_set_state(pipeline, GST_STATE_NULL);
gst_object_unref(pipeline);
I remind you that C and C++ do not have proper garbage collection, thus memory leaks are always a big danger, often underestimated by people with backgrounds in other languages. And being a C library, GStreamer does not use nicer C++ features like shared_ptr, but has its own version of reference counting, thus “unref”. GStreamer memory management is confusing, and leaks are a persistent risk. The general rule is like this: if you don’t need myBanana anymore, try:
gst_banana_unref(myBanana);
If no such function, try
gst_object_unref(myBanana);
If the code does not work, then you shouldn’t unref myBanana for some reason.
This is it for the minimal example. It wasn’t very hard, was it? If you want to know more about GStreamer in C++, read the official tutorial and our other examples like fun2 and capinfo. There are tons of other things, like creating a pipeline programmatically (not from a string), dynamic and on-request pads, working with caps and pads, etc.
GStreamer C++ appsink and OpenCV Example (Video 1)
But what if we want to process each video frame in our own C++ code, not in some standard GStreamer elements? There are two ways to do this:
- You can write your own element. This is hard for beginners, and I will not teach you this.
- Use appsrc and appsink to move data back and forth between pipeline and our C++ code. This is what we will do.
We start with an appsink video example, video1. We want to decode a video file with GStreamer into raw data, and then visualize each frame with OpenCV’s imshow(). We’ll walk through the code briefly (see video1.cpp in our repo for details). The pipeline is given by the string:
filesrc location=<…> ! decodebin ! videoconvert ! appsink name=mysink max-buffers=2 sync=1 caps=video/x-raw,format=BGR
Wow, appsink has a lot of options! Let’s examine them all:
- name=mysink : We have given our element a name so that we can find it.
- caps=video/x-raw,format=BGR : Caps are vital. Here we specify that we want a BGR raw video signal.
- sync=1 : We synchronize the data to play at the 1x speed. Try sync=0 for fun! Note: true==1, false==0.
- max-buffers=2 : Unlike most GStreamer elements, appsrc and appsink have their own queues. They can take a lot of RAM. This is an example of reducing the queue size. Only two frames are to be kept in memory, after that appsink basically tells the pipeline to wait, and it waits. Don’t try to reduce queues that much for branched pipelines!
If you need “global data” for a GStreamer pipeline it’s a good idea to create a structure for it, so that we will supply the data (as a pointer) to the callbacks if needed. In our case, all we need is the pipeline and the appsink element.
struct GoblinData {
GstElement *pipeline = nullptr;
GstElement *sinkVideo = nullptr;
};
We create an instance of this structure in main(), create the pipeline, and find the appsink by its name (“mysink”):
GoblinData data;
string pipeStr = “filesrc location=” + fileName + ” ! decodebin ! videoconvert ! appsink
name=mysink max-buffers=2 sync=1 caps=video/x-raw,format=BGR”;
GError *err = nullptr;
data.pipeline = gst_parse_launch(pipeStr.c_str(), &err);
checkErr(err);
MY_ASSERT(data.pipeline);
data.sinkVideo = gst_bin_get_by_name(GST_BIN (data.pipeline), “mysink”);
MY_ASSERT(data.sinkVideo);
Next, we play the pipeline:
MY_ASSERT(gst_element_set_state(data.pipeline, GST_STATE_PLAYING));
Now, we have to wait for the bus, which we now put into a separate thread, see the code for details:
thread threadBus([&data]() -> void {
codeThreadBus(data.pipeline, data, “GOBLIN”);
});
You can extract data from appsink by using either signals or direct C API, we chose the latter. We process data in a separate thread which we now start.
thread threadProcess([&data]() -> void {
codeThreadProcessV(data);
});
Finally, we wait for the threads to finish and stop the pipeline:
threadBus.join();
threadProcess.join();
gst_element_set_state(data.pipeline, GST_STATE_NULL);
gst_object_unref(data.pipeline);
Everything interesting happens in the function codeThreadProcessV(). It has an endless loop for (;;) { … } , which we will eventually break out of. What’s in the loop?
First, we check for EOS:
if (gst_app_sink_is_eos(GST_APP_SINK(data.sinkVideo))) {
cout << “EOS !” << endl;
break;
}
Next we pull the sample (a kind of data packet) synchronously, waiting if needed. For raw video, a sample is one video frame:
GstSample *sample = gst_app_sink_pull_sample(GST_APP_SINK(data.sinkVideo));
if (sample == nullptr) {
cout << “NO sample !” << endl;
break;
}
Now, we want to know the frame size. It turns out, that the sample actually has caps (don’t confuse it with the pad caps), and we can find the frame size in there:
GstCaps *caps = gst_sample_get_caps(sample);
MY_ASSERT(caps != nullptr);
GstStructure *s = gst_caps_get_structure(caps, 0);
int imW, imH;
MY_ASSERT(gst_structure_get_int(s, “width”, &imW));
MY_ASSERT(gst_structure_get_int(s, “height”, &imH));
cout << “Sample: W = ” << imW << “, H = ” << imH << endl;
Next, we extract a buffer (a lower-level data packet) from the sample. Note: in GStreamer slang, a “buffer” always means a “data packet”, and never ever a “queue”!
GstBuffer *buffer = gst_sample_get_buffer(sample);
Still, we don’t have a pointer to the raw data. For that we need a map:
GstMapInfo m;
MY_ASSERT(gst_buffer_map(buffer, &m, GST_MAP_READ));
MY_ASSERT(m.size == imW * imH * 3);
Now we can finally read the raw data (BRG pixels) via the pointer m.data. But we want to process the frame in OpenCV, so we wrap it in a cv::Mat.
cv::Mat frame(imH, imW, CV_8UC3, (void *) m.data);
Warning! Such a cv::Mat object does not copy the data, so if you want cv::Mat to persist when the GStreamer data packet is no more, or if you want to modify it, then clone it. Here we don’t have to (but we DO clone in video3). Now we can do anything we want with the cv::Mat image, but in this example, we just display it on the screen:
cv::imshow(“frame”, frame);
int key = cv::waitKey(1);
Now, we release the sample, and check if the ESC key was pressed:
gst_buffer_unmap(buffer, &m);
gst_sample_unref(sample);
if (27 == key)
exit(0);
We’re done with this frame, ready for the next one. In this example, we saw how to receive GStreamer video frames from appsink, and convert them into OpenCV images via the sample -> buffer -> map -> raw pointer -> Mat route.
GStreamer C++ appsrc and OpenCV Example (Video 2)
Now, the appsrc example, video2. Here we want to do the opposite to video1: read a frame from a video file with OpenCV’s VideoCapture and send it to the GStreamer pipeline to display on the screen with autovideosink. The pipeline is:
appsrc name=mysrc format=time caps=video/x-raw,format=BGR ! videoconvert ! autovideosink sync=1
The option format=time refers to timestamp format, NOT the image format from the caps! It is not required for video, but for some reason, it is required for audio appsrc, which will fail otherwise with rather obscure error messages (took me once a long time to figure this out).
This pipeline looks nice, but unfortunately, it will not work. If we try to play it, GStreamer will complain about the frame size. Indeed, we did not specify the frame size (width+height) in the appsrc caps, and it does not have a default one, so there is no way it can negotiate a frame size with the downstream pipeline. But we don’t know the frame size until we open the input file with OpenCV! How to solve this predicament? One could in principle defer creating the pipeline until we know the frame size, but it turns out that it is enough to defer playing it. This is exactly what we do in the function codeThreadSrcV(). In this function, we first open the input file with OpenCV and get the frame size and FPS:
VideoCapture video(data.fileName);
MY_ASSERT(video.isOpened());
int imW = (int) video.get(CAP_PROP_FRAME_WIDTH);
int imH = (int) video.get(CAP_PROP_FRAME_HEIGHT);
double fps = video.get(CAP_PROP_FPS);
MY_ASSERT(imW > 0 && imH > 0 && fps > 0);
Next, we create proper caps for our appsrc and set them with the g_object_set():
ostringstream oss;
oss << “video/x-raw,format=BGR,width=” << imW << “,height=” << imH <<
“,framerate=” << int(lround(fps)) << “/1”;
cout << “CAPS=” << oss.str() << endl;
GstCaps *capsVideo = gst_caps_from_string(oss.str().c_str());
g_object_set(data.srcVideo, “caps”, capsVideo, nullptr);
gst_caps_unref(capsVideo);
Now we can finally play the pipeline and start the infinite loop over frames:
MY_ASSERT(gst_element_set_state(data.pipeline, GST_STATE_PLAYING));
int frameCount = 0;
Mat frame;
for (;;) {
…
}
Inside the loop, we wait for the next frame from VideoCapture:
video.read(frame);
if (frame.empty())
break;
We create a GStreamer buffer and copy the data there, again using the raw pointers frame.data and m.data:
int bufferSize = frame.cols * frame.rows * 3;
GstBuffer *buffer = gst_buffer_new_and_alloc(bufferSize);
GstMapInfo m;
gst_buffer_map(buffer, &m, GST_MAP_WRITE);
memcpy(m.data, frame.data, bufferSize);
gst_buffer_unmap(buffer, &m);
Now we have to set up the timestamp. This is important because otherwise GStreamer would not be able to play this video at the 1x speed:
buffer->pts = uint64_t(frameCount / fps * GST_SECOND);
Finally, we “push” this buffer into our appsrc:
GstFlowReturn ret = gst_app_src_push_buffer(GST_APP_SRC(data.srcVideo),
buffer);
++frameCount;
Once we have exited the loop (upon the end-of-file), we want to shut down the pipeline gracefully by sending it an end-of-stream message.
gst_app_src_end_of_stream(GST_APP_SRC(data.srcVideo));
And now look at the code we described so far, and tell me: Is it good? It will run successfully if we start it, or at least seem to. But it has a serious flaw. Can you spot it? Pause for a moment and think carefully before reading any further.
![]()
You're thinking, right?
The answer is down below ⬇
Now, the answer. The VideoCapture decodes the video file as fast as it can, which can be quite fast on modern computers. However, our GStreamer pipeline is slow due to the sync=1 options (1x playback). But the pipeline will not signal our C++ code to slow down, the frame loop will run fast pushing more and more frames into the appsrc built-in queue, taking a lot of RAM, and possibly even crashing the application if the video is long enough.
This flaw (which is not obvious at all for beginners, by the way, did you guess it?) show how tricky designing pipelines (especially real-time ones) is, and how you should plan ahead and not code thoughtlessly. What is the solution? It’s obvious, we want the pipeline to signal when it wants data and when it doesn’t. Let’s register a couple of GLib-style signal callbacks on appsrc signals:
g_signal_connect(data.srcVideo, “need-data”, G_CALLBACK(startFeed), &data);
g_signal_connect(data.srcVideo, “enough-data”, G_CALLBACK(stopFeed), &data);
Since GLib is C and not C++, we cannot use lambdas or std::function in callbacks, only good old functional pointers. We supply the pointer &data to our data structure to make it usable by the callback functions. The callback functions simply set a single data flag:
static void startFeed(GstElement *source, guint size, GoblinData *data) {
using namespace std;
if (!data->flagRunV) {
cout << “startFeed !” << endl;
data->flagRunV = true;
}
}
static void stopFeed(GstElement *source, GoblinData *data) {
using namespace std;
if (data->flagRunV) {
cout << “stopFeed !” << endl;
data->flagRunV = false;
}
}
And now, we check this flag at the frame-processing loop and wait if the pipeline tells us to:
if (!data.flagRunV) {
cout << “(wait)” << endl;
this_thread::sleep_for(chrono::milliseconds(10));
continue;
}
Beautiful, isn’t it? Now we learned how to use appsrc in addition to appsink and move the data both ways. While there is no direct connection between OpenCV classes and GStreamer (at least not without third-party plugins), we can easily move the data around using raw pointers and a few lines of code. Who needs the ready-made code, when you can write your own?
More GStreamer C++ appsink + appsrc + OpenCV Examples
My tutorial has a few more examples for you which I will list very briefly.
- video3: This is like video1 and video2 combined. Here we have two pipelines, one with appsink (Goblin), the other one with appsrc (Elf) : We decode a video file with Goblin pipeline, process each frame with OpenCV, then send the frame to Elf pipeline to display it. This is the typical example of “decoding, then encoding with GStreamer”.
- audio1: The same with audio (no OpenCV in this code).
- av1: The same with both audio and video.
Conclusion
In this series of articles, I have introduced GStreamer, explained why it is important, and then showed how it can be used for computer vision and audio processing. Enjoy GStreamer!