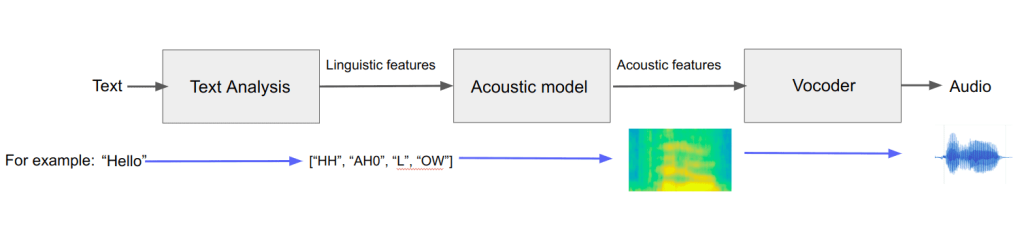
Historically, there have been many Deep Learning (DL) frameworks, like Theano, CNTK, Caffe2, and MXNet. Nowadays, they appear to be dead or dying, as just two frameworks heavily dominate the DL scene: Google TensorFlow (TF), which includes Keras; and PyTorch from Meta aka FaceBook. However, there is no reason to believe such a duopoly will persist forever. All the time, new DL frameworks are proposed. We have no idea which DL framework will be popular in, say, ten years.
One of the more serious contenders in the ”DL framework Junior League” is Google JAX. In this article, we examine JAX and look at its positive and negative sides. We will address questions like “When to use JAX?” and “Does JAX have any chance of success?”. But first, why was JAX created? We don’t know exactly, but apparently, AI folk in Google got fed up with TensorFlow and wanted a new toy to fool around with.
To understand JAX, note that Google has not one, but at least two (perhaps more) competing AI teams: Google Brain and DeepMind. They seem to never agree on anything. Even in the TensorFlow era, DeepMind used their own layer API called Sonnet (instead of the usual Keras). Probably nobody outside of DeepMind has ever heard of it. Now history repeats itself with JAX.
JAX ecosystem consists of the following packages (which are separate PIP packages):
- JAX: Low-level API (like torch without torch.nn or TF without tf.keras)
- FLAX (FLexible JAX): Layer API from Google (excluding DeepMind)
- Haiku: Another layer API, from DeepMind, inspired by Sonnet (TF)
- OPTAX: Optimizers and loss function for JAX
- Numerous more specialized packages: Trax, Objax, Stax, Elegy, RLax, Coax, Chex, Jraph, Oryx … . See the JAX ecosystem article.
Note that currently, JAX has no dataset/dataloader API, nor standard datasets like MNIST. Thus you will have to use either TF or PyTorch for these tasks or implement everything yourself.
JAX is open-source, it has pretty good documentation and tutorials. We also recommend AI Epiphany lectures on JAX and Flax. We assume that the reader has basic DL and python knowledge and some experience with either TF or PyTorch.
JAX: Basics, Pytrees, Random Numbers & Neural Networks
JAX Basics and Functional Programming
JAX (the low-level API) has two predecessors:
- autograd: Numpy-like library with gradients (backprop)
- Google XLA (accelerated linear algebra): fast matrix operations for CPU, Nvidia GPU and TPU. It compiles stuff into an efficient machine code. It is optional in TensorFlow, but required by JAX.
You can view JAX as “numpy with backprop, XLA JIT, and GPU+TPU support”. You write code like in numpy, but use the prefix jnp. (jax.numpy.) instead of np. . Then your code can run on CPU, GPU, or TPU with no changes. At least, this is the theory. Practice can be a bit harder. GPU installation requires precise versions of CUDA and CUDNN, just like for TensorFlow. It is only practical in Docker. However, unlike TF, JAX has no official docker images yet. And unless you work for Google, you will probably never see a TPU anywhere outside Google Colab.
Apart from the numpy-like API, JAX includes the following main operations:
- Calculate gradients with jax.grad()
- Compile python code to XLA with jax.jit()
- Add batch dimension to a function using jax.vmap() or jax.pmap()
The biggest difference between numpy and JAX is that JAX is heavily into functional programming; thus, JAX arrays (aka tensors) are always immutable. What does “functional programming” mean? It means that the python functions must be “pure”, e.g., behave like mathematical functions. In particular, a function f(x, y, z) is PURE if:
- It receives input data ONLY through the arguments x, y, z
- It outputs results ONLY through the return value(s)
- It does NOT modify objects x, y, z
- It does NOT access any global variables
- It does not print anything, does not access the screen, keyboard, any files or devices, or OS API
The function which breaks these rules is not pure, and we say that it has “side effects”. Such functions are not allowed in functional programming.
But what about classes and objects? The vanilla functional programming does not allow any classes. However, it would be highly impractical in Python, where we need classes for objects like multidimensional arrays. Thus JAX makes a compromise: classes and objects are allowed as long as they are strictly immutable: created once and never changed. What does it mean for DeepLearning? It means that any DL object, such as a model (neural net) or optimizer, must be separated into the immutable object (containing the code) and mutable parameters and state. In particular, the following data objects (usually python dictionaries) are separated from the main immutable objects (containing the code):
- Neural network parameters (which are trained)
- Neural network state (which is not trained, e.g., BatchNorm state)
- Optimizer state
- Random number generator (RNG) state.
Note that all this is very different from e.g. PyTorch, where a model, optimizer and RNG are all mutable objects under the hood, containing their own states and parameters. Moreover, the RNG is global. Functional programming in JAX makes things clearer for an experienced DL engineer, as you don’t have to worry about many ways the objects can be modified. All modifications are always explicit! On the other hand, it can make JAX harder to understand for beginners compared to PyTorch or TF.
How do you work with the immutable JAX arrays? A typical numpy code
a = np.arange(5.)
a[1:3] = [-1., -2.]
will not work in JAX, as the array a is modified in-place. Instead, you will have to write the following:
a = jnp.arange(5.)
a = a.at[1:3].set([-1., -2.])
Here, the object a is not modified but replaced by a new python object.
jax.jit(): Make a Python Function Run Much Faster
Suppose you have a python function my_function. According to JAX tutorials, you can make a python function faster by JIT-compilig it with jax.jit(). Actually, it’s compiling with XLA. Sounds too good to be true? It is.
Of course, magically accelerating any arbitrary python function will be impossible (unless you port it to C++). What’s the catch? Let’s see how exactly jax.jit() works. What happens when you type
fast_function = jax.jit(my_function)
?
- my_function is compiled from python to XLA. It’s achieved by tracing, similar to torchscript tracing in PyTorch. Actually, to be precise, the tracing happens when fast_function is called for the first time.
- Tracing takes significant time, so such “optimization” only makes sense if we are going to call fast_function repeatedly many times without recompiling.
- XLA is optimized to particular types of input arguments and particular shapes and dtypes of input jnp arrays. If input shape or type changes, fast_function is automatically recompiled, which takes time.
- Python statements such as if and for are not allowed unless they involve only arguments declared static. If the value of a static argument changes, the function is recompiled.
- Function my_function is supposed to be pure. In reality, if a side effect like print() is present, it works at the tracing stage, but NOT when running fast_function without recompiling.
Despite all these limitations, JIT can accelerate JAX code significantly when used correctly and is routinely used in most JAX codes.
Note that jax.jit() is often used as a decorator:
@jax.jit
def my_function(x):
…
jax.grad() : Gradients of a Scalar Function
Probably the most important JAX function is jax.grad(), which implements the gradients (backprop), which are a must for neural network training. Minimal example:
def f(x):
return jnp.sum(x ** 2)
gf = jax.grad(f)
x = jnp.array([1., 2., 3.])
print(f(x), gf(x)) # Prints 14.0 [2. 4. 6.]
Function f() must return a scalar. If it has multiple arguments, jax.grad() differentiates with respect to the first one. jax.grad() also uses tracing, but now if and for statements are allowed. A useful variation called jax.value_and_grad(f) creates a function which returns a tuple (f(x), grad(f)(x)).
jax.vmap() and jax.pmap(): Vectorize a Function along the Batch Dimension
Sometimes you have a function that works on, say, a vector, but you want to make it accept batches (one extra dimension). For example, let’s define a function:
def f(x):
w = jnp.array([[0., 0., 1.], [0., 1., 0.], [1., 0., 0.]])
return jnp.dot(w, x)
It works on the shape (3,) only, but not (B, 3), where B is the batch size. You can then transform function f with jax.vmap() to make it batch-compatible:
vf = jax.vmap(f) # Add a batch dimension to function
x = jnp.array([[1., 2., 3.], [4., 5., 6.]]) # shape (2, 3)
print(f(x)) # Error ! Wrong shape of x !
print(vf(x)) # Success : [[3., 2., 1.], [6., 5,. 4.]]
Note: this function is similar to the numpy-derived function jnp.vectorize(), but the two differ in details.
There is a parallel version called jax.pmap(), which distributes the computation across multiple XLA devices (GPUs, TPUs or CPU cores). Note that while CPU cores are separate devices, GPU cores are not. There is also a rudimentary API for inter-thread communication: psum(), pmean(), pmax(). Unfortunately, jax.pmap() strictly requires that the batch size B must be smaller or equal to the number of XLA devices. It is too stupid to distribute the threads otherwise! Note that if you are running on a CPU, by default JAX uses only one CPU core. To force JAX to use 8 CPU cores, write:
os.environ[‘XLA_FLAGS’] = ‘–xla_force_host_platform_device_count=8’
To check the available devices, write:
print(‘n_devices=’, jax.local_device_count())
print(‘devices=’, jax.devices())
JAX Pytrees
As we mentioned, various parameters and states must be kept separate from the immutable model objects. They are typically kept in a nested structure of python dict() and list() or similar classes. Such objects are called pytrees in JAX. Their leaves (lowest-level nodes) are typically JAX arrays.
Functions like jax.grad() support pytrees. For example, if the first argument p of a function f(p, x) is a pytree, the gradient with respect to p means a pytree of the same structure as p, consisting of gradients with respect to each leaf in p. This is a routine for neural nets; if f(p, x) is a JAX model, then the first argument p is typically a pytree of the network parameters (which we train).
There are a couple of useful functions to work with pytrees. jax.tree_map() applies a unary function to each node in a pytree, generating a new pytree of the same structure. For example, to print the pytree of the shapes of all parameters in the pytree t, type:
print(jax.tree_map(lambda x: x.shape, t))
A similar function jax.tree_multimap() applies a binary operation to two pytrees of the same structure. For example, the “sum of two trees t1 and t2” is given by:
jax.tree_multimap(lambda x, y: x+y, t1, t2)
JAX Random Numbers
Random numbers in JAX can confuse people who are used to numpy or PyTorch. Because of the functional programming paradigm, stateful or global random number generators (RNGs) are not allowed in JAX. How do you implement an RNG without a mutable state? Here we see the first example of how code and state are separated in JAX. Essentially the same logic applies to other objects like models and optimizers.
The function jax.random.normal() requires a “key”, which is the RNG state. You can create the key from a random seed like this (RNG initialization):
key = jax.random.PRNGKey(2022)
Then you can create a random array like this:
print(jax.random.normal(key, (2,)))
Everything works, right? Not really! If you put the same statement again, you will get exactly the same result:
print(jax.random.normal(key, (2,)))
This is the blessing and the curse of functional programming. Everything is explicit, predictable, clear, and immutable. In this case, the same state key results in the same random array.
How to generate random numbers properly? For that you need a function jax.random.split(), which generates two (or more) keys from the input key. Each key must be used only once (strictly !). Every time you need a random number, you write the following code:
key1, key = jax.random.split(key) # Split key1, update key
print(jax.random.normal(key1, (2,))) # Use key1 only once !
Don’t forget to split a new key (key1) every time you generate a new random number, because you can use each key only once! Alternatively, you can split multiple keys at once:
key1, key2, key3, key = jax.random.split(key, 4) # Generate 3 keys, update key
or even a list of keys:
*keys, key = jax.random.split(key, 10 + 1) # Generate a list of 10 keys, update key
One more thing: if a neural net requires an RNG for inference (e.g., it has dropout), the RNG key must be supplied explicitly at the inference time. You will see examples of this below.
Side note: of course, nothing stops you from using the numpy RGN and converting the result to JAX, but it is considered a bad style among JAX developers.
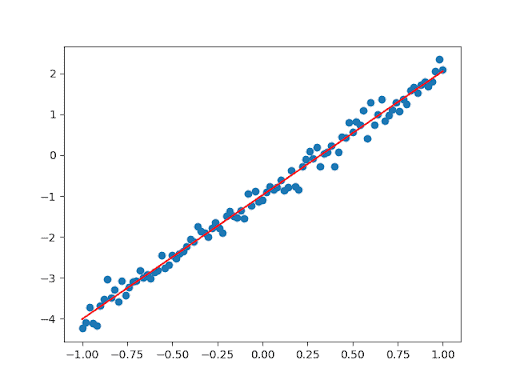
A Minimal Neural Net in Pure JAX
Let’s use our knowledge to code a trivial neural net in pure JAX. We want to implement a linear regression. Let’s create our data, a linear function plus some random noise:
n = 101
xx = jnp.linspace(-1, 1, n)
key_noise, key = jax.random.split(key)
yy = 3 * xx – 1 + 0.2 * jax.random.normal(key_noise, (n,))

Now we create a linear model with two parameters:
def model(params, x):
return params[0] * x + params[1]
Note how the first argument (which we usually take a gradient over) is a pytree of the optimizable network parameters (just a size-2 list in this case).
Next, we define a loss function, compile it with jax.jit(), and calculate its gradient (with respect to params):
@jax.jit
def loss_fun(params, x, y):
pred = model(params, x)
return jnp.mean((y – pred) ** 2)
vgl = jax.value_and_grad(loss_fun)
Finally, we initialize the parameters and perform the training loop:
params = [1., 1.]
lr = 0.1
for i in range(100):
loss, grad = vgl(params, xx, yy)
params = jax.tree_multimap(lambda p, g: p – lr*g, params, grad)
print(i, loss)
Note how we use jax.tree_multimap() to update our parameters (the vanilla SGD optimizer). The result looks like this:
OPTAX
This is going to be the shortest chapter of this article. In the previous example, we implemented vanilla SGD using jax.tree_multimap(). But we know it is better to use more advanced optimizers like Adam or SGD+momentum. Here, OPTAX comes to the rescue. Let’s see how we can modify the previous example using OPTAX. Since this is JAX, we must create an optimizer object (immutable, code-only) and then a state for it:
params = [1., 1.]
lr = 0.1
optimizer = optax.adam(learning_rate=lr) # Create the optimizer
opt_state = optimizer.init(params) # Init optimizer state
Next, we rewrite the training loop by using the optimizer:
for i in range(100):
loss, grad = vgl(params, xx, yy)
upd, opt_state = optimizer.update(grad, opt_state) # Optimizer step
params = optax.apply_updates(params, upd) # Basically params + upd
print(i, loss)
First, the method optimizer.update() calculates the updates plus the new optimizer state. Second, we add the updates to the params using optax.apply_updates(), which is basically just a sum of two pytrees using jax.tree_multimap() under the hood.
Note that we use the same OPTAX optimizers regardless of whether our model is written in pure JAX, FLAX, or Haiku. Apart from optimizers, OPTAX also contains several loss functions and schedulers.
FLAX
FLAX: Basics
FLAX (FLexible JAX) is a layer API for JAX created by Google (DeepMind excluded). It plays a role similar to Keras in TF or torch.nn in PyTorch. We are going to use the modern flax.linen API, typically imported as nn; the old API flax.nn is deprecated and removed!
Let’s create a FLAX model of a single linear (aka FC aka Dense) layer:
model = nn.Dense(features=3)
This creates an (immutable) model object, but we also have to create and initialize the model parameters. For that, you need two things: a single-use random key key_init, and a sample input x (to specify input shape):
x = jnp.ones((4, 2)) # Sample input: batch_size=4, dim=2
key_init, key = jax.random.split(key)
params = model.init(key_init, x)
Now, let’s print the parameter shapes:
print(‘params:’, jax.tree_map(lambda p: p.shape, params))
The output looks like this:
params: FrozenDict({
params: {
bias: (3,),
kernel: (2, 3),
}, })
What on earth is a “FrozenDict”? Basically, it’s an immutable python dict, defined in FLAX and registered with the JAX pytree ecosystem (which allows registering custom collection types). FLAX models prefer FrozenDict, but they can take python dict as well.
If the dictionary params consist of model parameters, why does it have a subdictionary named “params”? We’ll see it in a moment.
To run a model inference (or training) on a single input x, you type:
y = model.apply(params, x)
Note that you cannot use the parentheses operator! If the model requires a random key (e.g., for dropout), you’ll have to supply it as well:
y = model.apply(params, x, rngs={‘dropout’: key_do})
FLAX Models
But how can we create a FLAX model of more than one layer? There are several options. First, we can use sequential models (since FLAX 0.4.1):
model = nn.Sequential([
nn.Dense(features=5),
nn.relu,
nn.Dense(features=3),
])
Note that nn.Dense() is a FLAX model object, while nn.relu is a function (with no parameters), nn.Sequential() supports both.
For more serious models we’ll have to inherit the nn.Module class. Note that this class is a python dataclass (read about them if you didn’t already, they are fun):
class GoblinModel(nn.Module):
feat1: int
feat2: int
def setup(self): # This is called when init() is called
self.d1 = nn.Dense(self.feat1) # A Submodule is registered
self.d2 = nn.Dense(self.feat2)
def __call__(self, x):
x = jax.nn.relu(self.d1(x)) # Note: no apply(), no params !
return self.d2(x)
A dataclass defines several strictly-typed features (feat1, feat2 in our case) and automatically creates a constructor for them. That is why we should not define an explicit constructor in a dataclass, and the method setup() is used instead. It is called when you call the init() method of the model. Now we can create a model instance as usual followed by the initialization:
model = GoblinModel(5, 3) # (feat1, feat2)
x = jnp.ones((4, 7)) # Sample input: batch_size=4, dim=7
key_init, key = jax.random.split(key)
params = model.init(key_init, x)
A lot of magic happens under the hood when we call init(). It calls setup() and all submodules defined in setup() are registered, i.e. they are added to the parameter dictionary and initialized. Also init() handles random number keys under the hood and automatically generates a new single-use key for initializing each layer.
Note how in the __call__() method the submodules are called directly without giving them any parameters. When we run the inference, we actually call apply() and not __call__(), and the former method handles all parameters and passes all submodule parameters to the respective submodules.
However, the syntax with setup() is somewhat cumbersome, thus people often use the decorator nn.compact() (a lot of black magic happens in this function) to define the submodules directly in __call__():
class OrcModel(nn.Module):
feat1: int
feat2: int
@nn.compact
def __call__(self, x):
x = nn.Dense(self.feat1)(x) # Layer
x = jax.nn.relu(x) # Function
return nn.Dense(self.feat2)(x)
A CNN example (CNNs are popular in computer vision) is not much harder:
class DwarfCNN(nn.Module):
@nn.compact
def __call__(self, x):
x = nn.Conv(features=32, kernel_size=(3, 3))(x) # Layer
x = nn.relu(x) # Function
x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2))
x = nn.Conv(features=64, kernel_size=(3, 3))(x)
x = nn.relu(x)
x = nn.avg_pool(x, window_shape=(2, 2), strides=(2, 2))
return x
FLAX models (custom layers)
So far, we created models out of standard FLAX layers. But how do we create a custom one? Here is an example. We use the method param() to define parameters:
class ElfLinear(nn.Module):
feat: int
w_init: typing.Callable = nn.initializers.lecun_normal()
b_init: typing.Callable = nn.initializers.zeros
@nn.compact
def __call__(self, x):
w = self.param(‘w’, self.w_init, (x.shape[-1], self.feat))
b = self.param(‘b’, self.b_init, (self.feat,))
return x @ w + b
Due to the nn.compact() magic, we can declare the parameters directly in __call__() using the param() method. We need to supply an initializer and the shape. The latter is (in our example) derived from the input x, the sample input provided at the initialization.
The Problem of State
But what if our model has a state (variables that are NOT trainable parameters)? For example, BatchNorm and related ..Norm layers have a state, and so do all models containing a BatchNorm as a submodule. This is where FLAX gets a bit awkward, in our opinion. We initialize the model as usual:
vars0 = model.init(key_init, x)
However, now the FrozenDict vars0 contain not only parameters (in the section params), but also state variables in other sections. Now we have to separate the two by hand:
state, params = vars0.pop(‘params’)
It is very important that the optimizer optimizes only parameters (params) and not vars0! In other words, we use params when initializing the optimizer and performing the optimizer updates.
Before running apply(), we recombine parameters and state back into the dictionary vars, and use the form of apply() which updates the state. If we don’t want to update the state (a frozen BatchNorm at testing stage), we use the regular apply() instead:
vars = {‘params’: params, **state}
pred, state = model.apply(vars, x, mutable=state.keys())
Once again:
- We must separate all model variables into state and param.
- param (Network parameters) are optimized by the optimizer (via backprop).
- state (Network state, e.g. batchnorm state) is updated in apply() during training, but is frozen during testing.
Do you think handling all the different parameters and states is awkward? We agree. However, for common training scenarios, FLAX provides a higher-level API FLAX TrainState, which combines model, parameters, and optimizer together. You can try it if you want. This is the highest possible level DL API, like fit() in Keras, or PyTorch Lightning.
Haiku
Haiku basics
Haiku is another layer API from DeepMind. Compared to FLAX, it is even purer functional programming. In FLAX, a lot of magic was buried in the nn.Module class and nn.compact() function. In contrast, in Haiku a model class does not matter. There is a class hk.Module, but it’s a thin submodule container that does almost nothing, and you don’t have to use it at all if you don’t want to. All elven magic happens in the function hk.transform() and its variations. Let’s see how it all works.
A neural net is always defined as a function (similar to the functional definition in Keras), for example:
def forward(x):
return hk.Linear(3)(x)
Note that you define a Haiku module hk.Linear inside the function and do not provide any initialization data like input shape or a RNG key. Such a function will not work directly! Instead, you must transform it like this.
model = hk.transform(forward)
This step is similar to creating a functional Keras model (tf.keras.Model) in TensorFlow.
Now we get a transformed model object model. It works sort of like the FLAX module, but we never create such objects explicitly, only via hk.transform(). We still have to initialize it:
params = model.init(key_init, jnp.zeros((5, 2)))
Initialization is pretty much identical to the one in FLAX.
To run the model, we call apply():
y = model.apply(params, key_apply, x)
Note that in Haiku you must supply a RNG key in apply(), whether or not your model actually needs it (e.g., has dropout layers). If you want to get rid of this key, use an extra transformation:
model = hk.without_apply_rng(hk.transform(forward))
params = model.init(key_init, jnp.zeros((5, 2)))
y = model.apply(params, x)
A special version of hk.transform() is used when your model has a state (e.g. BatchNorm state):
model = hk.transform_with_state(forward)
params, state = model.init(key_init, x) # Init params + state
y, state = model.apply(params, state, key_apply, x) # Apply model, update state
Only params are optimized. Note how Haiku separates params and state automatically, while in FLAX you had to do it by hand.
Haiku models
How do you define a model in Haiku? First, you can inherit hk.Module:
class GoblinMLP(hk.Module):
def __init__(self, name=’goblin_mlp’):
super(GoblinMLP, self).__init__(name=name)
self.l1 = hk.Linear(5)
self.l2 = hk.Linear(3)
def __call__(self, x):
x = jax.nn.relu(self.l1(x))
return self.l2(x)
You’ll still have to define a forward function (or lambda):
def forward(x):
return GoblinMLP()(x)
But it’s Haiku, so you don’t have to use the model class if you don’t want to. How about this:
def forward_goblin(x):
x = hk.Linear(5)(x)
x = jax.nn.relu(x)
return hk.Linear(3)(x)
It works, you can actually register layers in the forward function, without using the hk.Module class at all!
If you are writing a custom module, use hk.get_parameter() to register network parameters:
class GoblinLinear(hk.Module):
def __init__(self, osize, name=’goblin_linear’):
super(GoblinLinear, self).__init__(name=name)
self.osize = osize
def __call__(self, x):
n_in, n_out = x.shape[-1], self.osize
w_init = hk.initializers.TruncatedNormal(1. / np.sqrt(n_in))
w = hk.get_parameter(‘w’, shape=[n_in, n_out], dtype=x.dtype, init=w_init)
b = hk.get_parameter(‘b’, shape=[n_out], dtype=x.dtype, init=jnp.ones)
return jnp.dot(x, w) + b
You can even use parameters directly in forward(), without any hk.Module.
Haiku has a couple of further nice things. You can define an MLP (multi-layer dense network) concisely (it uses ReLU by default, this can be changed):
hk.nets.MLP([20, 20, 1])
There is also a number of standard architectures (but alas no pre-trained weights for them):
hk.nets.MobileNetV1
hk.nets.ResNet18, 34, 50, 101, 152, 200
So, Can JAX Succeed?
We don’t know it. But here are the good and bad sides of JAX, in our opinion (as compared to PyTorch and TensorFlow):
The good:
- JAX is very TPU friendly and has built-in support for multiple devices.
- Functional programming makes things a bit cleaner (but only for pros).
- The weight of Google behind it should matter.
The bad:
- It is still in the 0.x versions, the API might change.
- Functional programming can be annoying for beginners.
- Apart from the TPU, there are few real advantages over PyTorch (or TF).
- There are very few deploy options. Currently, there is only the experimental jax2tf converter. No ONNX, tflite or TensorRT.
- There is no dataset/dataloader API.
- There are still very few existing or pre-trained models (but see flaxmodels).
Have fun and enjoy JAX! And if we you are more into video content, we have a lecture on JAX on our YouTube channel:
P.S. If the author were Google, he would create some nice deployment system for JAX, like tflite, but based on XLA, with versions for C++, Android, iOS, embedded and Web browser.