Practical Guide to Real-Time Video Pipelines: Tools, Techniques & Optimization
Video is an extremely popular way to represent information. Indeed, sometimes, it is enough to watch a short clip instead of listening to a podcast or reading about complicated technical concepts.
Businesses also strive to gain a competitive advantage by integrating innovations like video analytics, streaming services, robotics, and AR/VR apps. To get valuable insights from raw video data, you need to design and implement efficient video pipelines.
From a user’s point of view, a video is simply a sequence of images displayed one after another with a very short inter-frame interval. Typically, it has around 30 frames per second (FPS). However, many things are left inside the box.
In this article, we focus on how to build an efficient video streaming pipeline and explore:
- What is a video pipeline from a technical perspective.
- Essential elements of video pipelines.
- Ways to design and develop efficient video pipelines.
- Share our It-Jim experience and best practices for building a video pipeline.
- Tools, frameworks, and technologies for building video pipelines.
Let’s explore what a video pipeline means and how it is utilized in computer vision, compared to traditional image processing methods.
Understanding Video Pipelines
So, what is a video pipeline?
At its core, a video pipeline is a sequence of processing steps that takes raw video from cameras or sensors and turns it into output or actionable insight for the end user. This technology is used in computer vision systems for object detection, tracking, and monitoring.
The primary goal for developers is to maintain high video quality while optimizing storage, scalability, and seamless playback across various devices and networks.
The main components of a video pipeline are input sources, transcoding servers, content delivery networks (CDNs), and processing tools. Once these video pipeline components are aligned to work together, the system delivers a smooth viewing experience and is a reliable analytics tool.
Traditional image processing works with single, static images. There’s no pressure to process them quickly, so it’s often done offline without time constraints.
In contrast, video processing pipelines work with a stream of frames. Each frame arrives in rapid succession and is connected to the ones before and after it. For many use cases, such as live streaming, surveillance, or AR/VR, each frame must be processed in real-time or near real-time to ensure smooth playback and timely analysis.
Real-time pipelines differ from non-real-time ones in that they are designed to operate with minimal delay, often under hardware constraints. Real-time video pipelines process frames as they arrive, prioritizing low latency and smooth playback for live applications.
Non-real-time pipelines handle pre-recorded video, allowing slower, more complex processing without time constraints. Both types share the same components but differ mainly in timing and performance requirements.
In summary, either system requires a real or non-real-time video pipeline setup; the process can be complex and costly. Next, we will outline the key aspects of its careful planning and implementation.
How Video Pipelines Work
A video pipeline consists of several phases, including capture, processing, and encoding. Here is the workflow of a standard video pipeline:
- Capture raw video through a camera.
- Process the video (apply filters, AI models, or CV algorithms).
- Encode it for storage or streaming.
- Repackage frames for storage or transmission.
- Deliver output to the user or system.
The first steps in a video pipeline are capturing raw video, uploading it to a server or cloud storage, and extracting metadata from the original video.
Whether you’re building a smart surveillance system, a robotics platform, or a live video analytics service, your video pipeline has a direct impact on the accuracy and performance of your solution.
Key Components of Video Pipelines
The main components of a video pipeline are video sources, transcoding servers, Content Delivery Networks (CDNs), and various processing tools.
Thus, most of the video pipeline consists of the following:
- Video sources – these can include a camera, video files, or a live stream.
- Encoding and decoding – the process of converting video into different formats for storage and transmission.
- Transcoding – convert video from one format to another, also for different platforms or devices.
- CDN integration – distribute video content through a network of servers to reach users faster.
- Display elements – prepare the video for playback on various devices (e.g., TVs, computers, mobile phones).
A well-tuned video pipeline seamlessly integrates all its video pipeline components. A good understanding and implementation of the components can make a big difference to the efficiency and reliability of your video pipeline.
Next, you can check out an example with code samples on how to build a video pipeline.
Building Efficient Real-Time Video Pipelines
Have you ever written your own video player? What about a media server? Or a real-time video processing pipeline?
For most people in the world, the answer is “no”. Probably even among the readers of this blog.
Our experience suggests that many people underestimate the difficulties involved and are in for unpleasant surprises when attempting to implement computer vision (CV) in real-time.
“Real-time” refers to the process of receiving frames from a camera or network stream, as opposed to a pre-recorded video file.
Novice computer vision engineers typically learn their craft on individual images. In rare cases, when the time dimension is required (e.g., tracking, optical flow), they usually work on pre-recorded videos.
Then they think: What can go wrong with real-time? I just get frames from the camera and apply the fancy computer vision that I usually do?
A schematic C++ code they imagine looks like this:
cv::VideoCapture cap(cv::CAP_ANY);
while (true) {
cv::Mat frame;
cap.read(frame);
process_somehow(frame);
send_somewhere(frame);
}
Is it how a good real-time computer vision system works? No! Let’s dive deeper.
Where is the Frame Loss?
When junior CV engineers try to do something with a camera, our first question is, “Where is the frame loss here?”
This question usually surprises people: “No, I do not want to lose any frames”. This is wrong. If your camera produces 30 FPS, few CV algorithms (and especially not neural networks) can process a frame in 33 milliseconds.
Then, you typically want to stream, display on screen, or record the result somewhere. This also takes time. Even if your computer is fast enough, there are always slower devices (such as embedded ones) or computers overloaded with some background tasks.
So, frame loss is inevitable. And because of the frame loss, you can never rely on a steady FPS from a camera.
Pop Quiz: Where is the frame loss in the piece of code above? Think before reading the answer.
Now, here is the answer: the frame loss is at the line “cap.read(frame);”. This is a synchronous waiting call “give me the next frame when ready”. If you take too long processing frame 1, the subsequent frames will be lost until you reach the read() call again.
Luckily for us, OpenCV VideoCapture does not try to keep multiple frames in a buffer. You can guess what would happen if it did.
Hint: Nothing good.
Again, frame loss means that there is no reliable fixed frame rate (FPS) and that the difference between the timestamps of two subsequent frames varies.
It does not matter if your CV algorithms process each frame individually. It is usually not critical for optical flow either.
However, if you perform signal processing in the time domain or use parameterized motion models, then frame loss becomes critical.
What is the solution?
You must record the original timestamp of each frame. If you need a signal with a regular frame rate (FPS), resample the original video to a desired regular timestamp grid.
Threads and Buffers to the Rescue
Does the code above work correctly? Yes. Is it efficient? Definitely not.
Note how it does all operations strictly sequentially. This includes an input (get a frame from the camera) and output (visualize the result on the screen, write it to a file, or send it to the network).
Such a sequential pipeline does not utilize (or at least does not utilize efficiently) multithreading on multiple CPU cores (and possibly a GPU also).
But the sequential pipeline has an even more striking defect.
Imagine for a moment that you want to process your frame in the cloud, and then send the result back to the edge device. Processing on the server can be very fast, but the internet connection has a lag, sometimes up to half a second or more (in two directions).
With a sequential pipeline, you will wait for half a second for the answer from the server before processing the next frame. The result is 2 FPS or less, whereas with a proper pipeline, you can achieve 30 FPS with in-cloud processing.

Figure 1. Car assembly line (© www.freepik.com)
This is similar to a car assembly line, as shown in Figure 1.
As you can observe from the sequential pipeline in Figure 2, this means that only one car is being assembled at a given time.
Imagine an almost empty factory building with one very lonely car traveling the assembly line. Only when this car is finished can the next car start. That would not be an efficient assembly line. But we all know that is not how car factories work in real life.
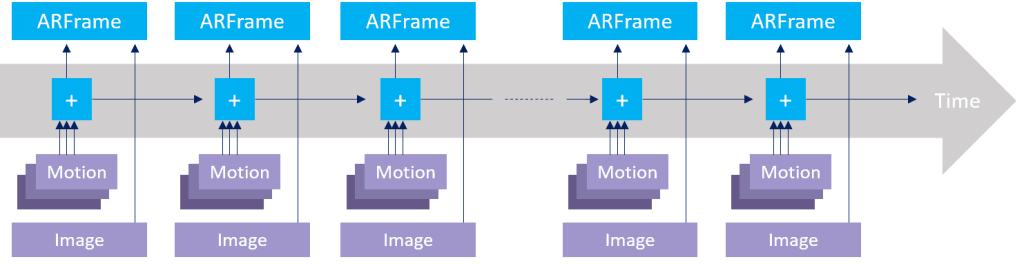
In reality, multiple cars move along the assembly line, one after another. The same principle applies to serious real-time computer vision, as shown in Figure 3. Different stages in the pipeline (“actions”) take place in different threads, running on different CPU cores or possibly on a GPU.

Figure 2. A sequential pipeline. A frame from the camera travels through the pipeline (actions 1, 2, and 3) and is finally sent to the “Output” (e.g., visualization on the screen). When this frame processing is finished, we can receive the next frame from the camera.
Frames travel along the pipeline like cars on the assembly line, from thread to thread. While thread 3 processes frame 7 (for example), thread 2 can process frame 8 at the same time, and thread 1 can process frame 9.
The “actions” include different computer vision operations that are executed sequentially, for example, object detection and rendering of some graphics. This also includes video encoding and decoding, BGR <-> YUV conversions, CPU <-> GPU data transfer, etc.
There is, however, a subtle difference.
On the assembly line, cars travel at a fixed speed (throughput), and each assembly operation takes a standard “one step” time (or less).
In video pipelines, maintaining a consistent FPS can be challenging, and computer vision operations may take varying times on different frames.
So, what is usually done?
The threads on the pipeline are connected by buffers (queues). The buffers have a maximal size that they are not allowed to exceed. If the buffer is overfilled, the frame is lost (something that we would not want on a car assembly line).
Thus, if we have a bottleneck in the pipeline (thread with extended processing time), the frames are automatically lost in the buffer just before this thread. This basic pipeline architecture (threads connected with buffers) is found behind the hood in every media player or server, in YouTube, Zoom, Skype, and Netflix.
And if you want your video pipeline to work correctly, you should implement this architecture as well. Alternatively, you can use a ready-made tool (see below).
Note that buffers introduce latency. On the other hand, they ensure smooth playback. There is always a trade-off between smoothness and latency; you cannot have both. If you want a low-latency real-time pipeline, keep your buffers as small as possible.

Figure 3. A multithreaded buffered pipeline. Threads are connected via buffers.
One thing is essential. Never build an unlimited buffer without a size limit. It will grow infinitely (while generating a rapidly increasing lag), fill all RAM, and eventually crash your computer.
This is not a purely theoretical possibility. Frame loss is the safety valve in your pipeline, preventing it from exploding like an overheated steam engine. When using higher-level libraries and frameworks, be aware that they may implement their buffers.
Always understand how the library functions work, and read the documentation carefully.
For example, the read() method of cv::VideoCapture provides the next camera frame, but what exactly does it mean? It is a combination of grab() and retrieve(). grab() grabs the last camera frame (or waits for the next one), while retrieve() decodes it to the BGR format if needed.
There is no buffer anywhere. Lucky for you, you cannot shoot yourself in the foot with OpenCV. But suppose some other hypothetical camera library implemented an unlimited buffer; what would then? Then, we would crash the computer by grabbing frames too slowly.
Note: The often-used logic “Send frame to the engine if the engine is available. If the engine is busy, drop the frame” can be viewed as a very rudimentary buffer with a maximum size of 0. The proper buffers are more flexible than that.
A Note on Asynchronous Programming
Asynchronous programming is a popular trend nowadays, especially in web programming, as well as in mobile and desktop GUIs.
What does it mean?
A synchronous operation means that you request some action and wait for it to finish. For example, the above-mentioned read() method of cv::VideoCapture waits for the next video frame to arrive.
An asynchronous operation means that you request something and provide a callback function that will be called when the operation is finished. This is like your boss telling you, “Do something, then text me when you are ready”. Of course, your boss will not wait for you to finish; he will do some other work.
In particular, in web and mobile, cameras and video streams typically work this way. You have to provide a callback cb(), which is called when the next frame arrives.
What does it mean?
Attentive readers may notice that this logic is mathematically not well-defined. What happens if frame 2 arrives when frame 1 is still being processed (callback did not return)?
Different libraries behave differently. Always understand how yours does. The library may lose a frame; this is good.
Or it can implement its own buffer.
Or, the callback for frame 2 will be called anyway in another CPU thread, while frame 1 is still being processed.
The last option is interesting. Many CV algorithms (optical flow, tracking, etc.) require frames to arrive purely sequentially, one after another. The algorithm will go crazy if you try to run it for two frames simultaneously in different threads, crashing, throwing an exception, or, worse, behaving erratically.
Even single-frame algorithms (like object detection neural networks) will eventually crash your device if you try to run many frames simultaneously in different threads. Such a situation happens all the time in real life when some web or mobile developer simply puts your algorithm in a callback without thinking about pipelines or buffers at all.
The correct solution is to put a buffer between the callback and algorithms. The callback should simply put a frame into the buffer, a fast operation (in general, callbacks should NOT contain any heavy operations).
At the same time, the CV algorithm in another thread reads frames from the buffer. It ensures the proper sequence of frames, and of course, the buffer should have a maximum size and frame loss, as usual. You have to implement the buffer yourself.
Decoding, Encoding and YuV
How to decode and encode videos?
At least in Linux, there are different libraries for different audio and video codecs (libx264, libvpx, etc.) with different obscure APIs.
Is there a unified approach for all codecs? Yes, there are a few options.
OpenCV uses ffmpeg under the hood and can handle simple cases, but it is vastly insufficient for serious projects. FFmpeg and GStreamer are two principal choices, at least on Linux and cross-platform. Of course, they also exist on Windows, macOS, and mobile devices. You should master these two libraries if you do video pipelines.
Most video codecs do not work with BGR or RGB images. Instead, they use various versions of YuV, including YuV420p, NV12, and NV21. If you want RGB, you will generally have to convert it yourself.
OpenCV can handle a few versions of YuV, and libswscale (a part of FFmpeg) can handle them all.
Note that YuV<->RGB conversions are pretty expensive, especially on 4K images.
You should avoid them if possible. For example, if your CV algorithm processes grayscale images, you do not need RGB and can work on YuV directly (as the grayscale frame is always a part of YuV frame).
What about hardware-accelerated encoders/decoders, such as those available on Nvidia GPUs (including the Jetson Xavier, but excluding those in laptops) and Raspberry Pi?
FFmpeg and GStreamer can generally handle those, but sometimes it requires building the library from source (e.g., FFmpeg on Raspberry Pi, which is a significant pain).
There are also native APIs for Nvidia (NVENC/NVDEC) and for Raspberry Pi (MMAL, OpenMAX). You may encounter issues with hardware encoders and decoders.
For example, in one project, we figured out that the Nvidia H264 decoder produces only NV12 (and not the regular YuV420). Also, some hardware encoders do not repeat PPS/SPS packets (headers) of H264, which causes bad issues with streaming.
Let us cheat!
Despite your best efforts, you may find that your pipeline’s output looks ugly in terms of throughput (FPS), latency (lag), and stability.
For example, if some neural network takes 0.5 seconds per inference, you will get a 2 FPS video with over 0.5 seconds lag. Ouch.
Then, how come all commercial products, including mobile, browser, and embedded apps, all look so beautiful? First, they optimize everything that can be optimized. Second (and we are revealing to you the biggest secret in the industry), they cheat. Everybody does. By “cheating,” we mean an optimization that radically changes the entire pipeline logic to produce a visually pleasing output.
1. Show every frame (keep full FPS), process only some of them.
In the example above, the output video of 2 FPS is very ugly. So, send only 2 frames per second to the slow neural network (which can do, e.g., object detection), but send every single input frame (30 FPS) to the output video.
This is essentially a pipeline with branches as opposed to a sequential one. A massive frame loss happens on the detection branch (as the detector is slow) but not on the visualization branch.
But how do we visualize detected objects in every frame, when detection happens only twice per second? You can use the last detected position. Or, better, look at cheat # 2.
2. If detection is slow, interpolate, smooth or track.
When doing cheat #1, you can interpolate/extrapolate object locations between the “detection” frames or apply some kind of smooth motion models with velocity parameters. Even when detection is fast, a good motion model provides a much smoother visual representation of object motion.
Accurate tracking involves using optical flow and similar approaches to track each object as soon as it is detected.
3. Prefer zero lag and compensation.
Visible lag makes things ugly. If the camera feed on your smartphone’s screen is 0.5 seconds delayed, people tend to notice this.
Thus, when using cheat #1, it is better to visualize the frame immediately, rather than waiting for the results of object detection.
Most real-time apps, especially on mobile, work like this. Of course, this kills the synchronization between the frame and the detection result. You might notice that detection results are lagging half a second behind the frame, since they were detected on an earlier frame.
Bad. But this is a necessary evil. If the entire camera video lags, it is visually much worse than if a little bounding box lags.
What you can try is to compensate for the lag. If you have some motion model for the object, you can just go 0.5 seconds back in time. This works reasonably well, but only when the object moves predictably and not when a new object is just detected.
When you think that your app looks poor compared to existing ones, remember that true computer vision professionals are masters of cheating.
Tools and Frameworks for Video Pipeline Development
Building a video pipeline requires using the right tools and libraries that cover different aspects of video processing.
Here are some of the most commonly used tools:
- GStreamer: Modular, real-time streaming and processing.
- FFmpeg: Powerful CLI/media processing toolkit.
- OpenCV: Offers tracking, filtering, and vision utilities.
- Nvidia DeepStream: Optimized for GPU-accelerated inference.
- Jetson APIs, MediaPipe, VAAPI: Platform-specific hardware acceleration.
1. GStreamer
This is a multimedia framework for building graphs of media-handling components. GStreamer supports real-time audio and video processing. The tool is best for live streaming and conferencing solutions with support for custom plugins, codecs, and protocols.
2. FFmpeg
This open-source library supports video encoding, decoding, transcoding, streaming, and other related tasks. The tool supports a wide range of file formats and codecs (e.g., H.264). FFmpeg is typically used for video format conversion, frame extraction, or video compression.
3. OpenCV
OpenCV (Open Source Computer Vision Library) focuses on real-time image and video processing. The tool is used for frame capturing, object detection and tracking and is valuable for vision-intensive tasks such as motion tracking or AR in video pipelines.
4. Nvidia DeepStream
This is an AI streaming toolkit designed for Nvidia GPUs and real-time analytics. The technology enables high-performance deep learning inference (e.g., object detection and classification). Nvidia DeepStream is best suited for scalable, low-latency pipelines with advanced AI capabilities.
5. Hardware APIs
In addition to software libraries, hardware APIs provide access to specialized encoding and decoding capabilities to improve performance and reduce latency. For example, you can use Nvidia’s NVENC and NVDEC or platform-specific APIs like OpenMAX. Using these APIs can greatly improve throughput and efficiency in video pipelines, especially for high-resolution or real-time applications.
Before selecting video processing tools, consider the following aspects:
- Scalability and performance for your project.
- Compatibility with devices to keep pipeline performance.
- Scalability and maintenance via cloud storage solutions.
6. Integrating AI and Automation
Adding Artificial Intelligence to your video pipeline makes it more efficient, streamlines processes, and reduces manual work. AI and machine learning can:
- Automate video indexing.
- Generate captions or subtitles.
- Detect inappropriate content.
- Optimize video quality in real-time based on user preferences.
- Improve accuracy and consistency in video processing tasks.
AI-driven techniques provide a more responsive and adaptive video pipeline that delivers high-quality content in real-time.
By using these tools, you can build efficient, scalable, and feature-rich video pipelines for your project.
Video Pipelines: Best Practices and Industry Techniques
Building a video pipeline that’s efficient and reliable requires a mix of technical knowledge, practical experience, and industry-proven methods.
Here are some best practices used in the field from real-world examples and companies like Netflix and computer vision experts like It-Jim:
- Frame skipping and interpolation: to prevent overloads in video pipelines, process or display key frames selectively. This way, you can have smooth playback even under heavy processing loads.
- Progressive rendering: deliver a lower-quality version of the video quickly. Then you can progressively improve the quality as more data is processed, reducing perceived buffering times.
- Adaptive bitrate streaming: adjust video quality based on network conditions to minimize buffering, ensure smooth playback and enhance viewer’s perception of performance.
- Preloading and caching: use preloading strategies and cache frequently accessed video segments at edge servers or CDNs to reduce latency and speed up playback start times.
You can avoid some common pitfalls in building a video pipeline by following these recommendations:
- Managing frame loss: design real-time video pipelines to handle frame loss by recording original timestamps and resampling frames to maintain temporal consistency.
- Buffer size control: buffers should strike a balance between latency and smooth playback. Implement strict size limits on buffers to prevent memory exhaustion and system crashes.
- Efficient format conversions: minimize expensive video format conversions (e.g., YUV to RGB) to reduce processing overhead.
- Multithreading and asynchronous processing: use multithreading to leverage multiple CPU cores. You can also employ asynchronous programming to avoid blocking operations and reduce latency.
- Microservices architecture: break the pipeline into decoupled microservices to improve flexibility, scalability, and maintainability, and to speed up feature development and troubleshooting.
- Hardware acceleration: use hardware encoders and decoders (e.g., Nvidia NVENC/NVDEC) and platform-specific APIs to reduce encoding and decoding latency and CPU load.
- Comprehensive monitoring and analytics: implement detailed logging, quality metrics, and monitoring tools to quickly identify bottlenecks, failures or quality degradation.
- Security: integrate security measures like Digital Rights Management (DRM) early in the pipeline to protect content without compromising performance.
By applying these best practices, engineers can build video pipelines that deliver high-quality, low-latency video experiences at scale. At the same time, these approaches enable the mitigation of typical challenges faced in production.
Efficient Video Pipelines Summary
- Do not use sequential single-thread pipelines
- Frame loss is inevitable
- There is no stable, predictable FPS; if you need one, resample
- Build a pipeline with threads and buffers
- Never do an unlimited buffer/queue
- Do not put heavy operations into asynchronous callbacks
- Asynchronous callbacks must not run sequentially
- Use FFmpeg, GStreamer, or other software for encoding/decoding
- Codecs always use YuV, and many versions of it
- Avoid costly YuV<->RGB conversions if possible
- Don’t reinvent the wheel, use GStreamer!
- Or Nvidia DeepStream for a GPU-only pipeline, which can run out of GPU RAM
- Cheat #1: Show every frame (keep full FPS), process only some of them
- Cheat #2: If detection is slow, interpolate, smooth, or track
- Cheat #3: Prefer zero lag and compensate
Final Word on Video Pipelines
We have addressed some practical aspects of video processing pipelines and shed light on people who might think that this is a trivial process.
When developing video pipelines, engineers must find a proper balance between speed, accuracy, and usage of available software and hardware resources. Solutions often involve queue buffering, multithreading, and modular design of the video pipeline.
Also, incorporating AI into video pipelines can automate repetitive tasks, significantly enhancing workflow efficiency. In any case, the key to success lies in careful planning, choosing the right tools, and optimizing workflow.













 frugally-deep: This is more of a curiosity than a real thing. Frugally-deep is a header-only C++ library, which requires 3 more header-only libraries including Eigen. It infers a neural network (described as a JSON file) on the CPU using Eigen. OpenCV images can be used as input/output. There is a converter for Keras models. While not especially efficient, frugally-deep can be used for deploying lightweight models easily, or as a toy for deep learning beginners. Now let’s see what the big corporations can offer.
frugally-deep: This is more of a curiosity than a real thing. Frugally-deep is a header-only C++ library, which requires 3 more header-only libraries including Eigen. It infers a neural network (described as a JSON file) on the CPU using Eigen. OpenCV images can be used as input/output. There is a converter for Keras models. While not especially efficient, frugally-deep can be used for deploying lightweight models easily, or as a toy for deep learning beginners. Now let’s see what the big corporations can offer. Microsoft: ONNX runtime: It is an inference-only framework for Python and C++, CPU and Nvidia GPU, which can infer ONNX models. ONNX is the Microsoft format for neural networks, which is (in theory) framework-agnostic and can (in theory) be used to transfer any network from any training framework to any inference framework. An ONNX model can be exported from PyTorch or Tensorflow (provided that your network is good enough, see the next section). The C++ version of ONNX runtime has to be built from the source.
Microsoft: ONNX runtime: It is an inference-only framework for Python and C++, CPU and Nvidia GPU, which can infer ONNX models. ONNX is the Microsoft format for neural networks, which is (in theory) framework-agnostic and can (in theory) be used to transfer any network from any training framework to any inference framework. An ONNX model can be exported from PyTorch or Tensorflow (provided that your network is good enough, see the next section). The C++ version of ONNX runtime has to be built from the source. Nvidia: TensorRT : It is a C++ inference framework for Nvidia GPUs only, and the absolutely fastest inference framework for Nvidia GPUs. It should be always considered to be the default option for GPU deployment. TensorRT supports FP16 and INT8 inference and other fancy optimizations. Unlike other frameworks, it is not open-source (though free). It can import networks in ONNX, UFF and Caffe formats. I will discuss TensorRT in more detail in a separate section below. A python wrapper is advertised, but it only works on Python 3.6.
Nvidia: TensorRT : It is a C++ inference framework for Nvidia GPUs only, and the absolutely fastest inference framework for Nvidia GPUs. It should be always considered to be the default option for GPU deployment. TensorRT supports FP16 and INT8 inference and other fancy optimizations. Unlike other frameworks, it is not open-source (though free). It can import networks in ONNX, UFF and Caffe formats. I will discuss TensorRT in more detail in a separate section below. A python wrapper is advertised, but it only works on Python 3.6.







